This analogy has one major flaw, when running programs in UNIX they actually run simultaneously. UNIX is multitasking, Pike is not. When one object is executing code, all the other objects has to wait until they are called. An exception is if you are using threads as will be discussed in a later chapter.
In my experience, the advantages of object oriented programming are:
Similarly, if you want to load another file and call functions in it, you can do it with compile_file(), or you can use the cast operator and cast the filename to a string. You can also use the module system, which we will discuss further in the next chapter.program scriptclass=compile_file(argv[0]); // Load script
object script=scriptclass(); // clone script
int ret=script->main(sizeof(argv), argv); // call main()
If you don't want to put each program in a separate file, you can use the class keyword to write all your classes in one file. We have already seen an example how this in chapter 4 "Data types", but let's go over it in more detail. The syntax looks like this:
This construction can be used almost anywhere within a normal program. It can be used outside all functions, but it can also be used as an expression in which case the defined class will be returned. In this case you may also leave out the class_name and leave the class unnamed. The class definition is simply the functions and programs you want to add to the class.class class_name {
class_definition
}
To make it easier to program, defining a class is also to define a constant with that name. Essentially, these two lines of code do the same thing:
Because classes are defined as constants, it is possible to use a class defined inside classes you define later, like this:class foo {};
constant foo = class {};
class foo
{
int test() { return 17; }
};
class bar
{
program test2() { return foo; }
};
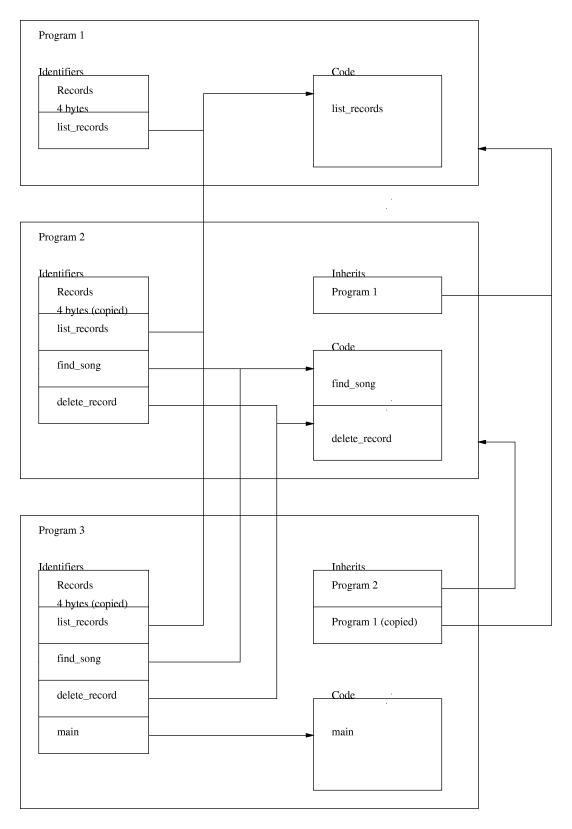
What inherit does is that it copies all the variables and functions from the inherited program into the current one. You can then re-define any function or variable you want, and you can call the original one by using a :: in front of the function name. The argument to inherit can be one of the following:inherit "hello_world";
int main(int argc, array(string) argv)
{
write("Hello world version 1.0\n");
return ::main(argc,argv);
}
Let's look at an example. We'll split up an earlier example into three parts and let each inherit the previous part. It would look something like this:
As you can see it would be impossible to separate the different read and main functions without using inherit names. If you tried calling just read without any :: or inherit name in front of it Pike will call the last read defined, in this case it will call read in the fourth inherit.inherit Stdio.File; // This inherit is named File
inherit Stdio.FILE; // This inherit is named FILE
inherit "hello_word"; // This inherit is named hello_world
inherit Stdio.File : test1; // This inherit is named test1
inherit "hello_world" : test2; // This inherit is named test2
void test()
{
File::read(); // Read data from the first inherit
FILE::read(); // Read data from the second inherit
hello_world::main(0,({})); // Call main in the third inherit
test1::read(); // Read data from the fourth inherit
test2::main(0,({})); // Call main in the fifth inherit
::read(); // Read data from all inherits
}
If you leave the inherit name blank and just call ::read Pike will call all inherited read() functions. If there is more than one inherited read function the results will be returned in an array.
Let's look at another example:
This short piece of code works a lot like the UNIX command cat. It reads all the files given on the command line and writes them to stdout. As an example, I have inherited Stdio.File twice to show you that both files are usable from my program.#!/usr/local/bin/pike
inherit Stdio.File : input;
inherit Stdio.File : output;
int main(int argc, array(string) argv)
{
output::create("stdout");
for(int e=1;e<sizeof(argv);e++)
{
input::open(argv[e],"r");
while(output::write(input::read(4096)) == 4096);
}
}
The following table assumes that a and b are objects and shows what will be evaluated if you use that particular operation on an object. Note that some of these operators, notably == and ! have default behavior which will be used if the corresponding method is not defined in the object. Other operators will simply fail if called with objects. Refer to chapter 5 "Operators" for information on which operators can operate on objects without operator overloading.
|
Here is a really silly example of a program that will write 10 to stdout when executed.
It is important to know that some optimizations are still performed even when operator overloading is in effect. If you define a multiplication operator and multiply your object with one, you should not be surprised if the multiplication operator is never called. This might not always be what you expect, in which case you are better off not using operator overloading.#!/usr/local/bin/pike
class three {
int `+(int foo) { return 3+foo; }
};
int main()
{
write(sprintf("%d\n",three()+7));
}
void find_song(string title) |