14.11 MIME
RFC1521, the Multipurpose Internet Mail Extensions memo, defines a structure which is the base for all messages read and written by modern mail and news programs. It is also partly the base for the HTTP protocol. Just like RFC822, MIME declares that a message should consist of two entities, the headers and the body. In addition, the following properties are given to these two entities:- Headers
- Body
The Message class does not make any interpretation of the body data, unless
the content type is multipart. A multipart message contains several
individual messages separated by boundary strings. The create
method of the Message class will divide a multipart body on these boundaries,
and then create individual Message objects for each part. These objects
will be collected in the array body_parts within the original
Message object. If any of the new Message objects have a body of type
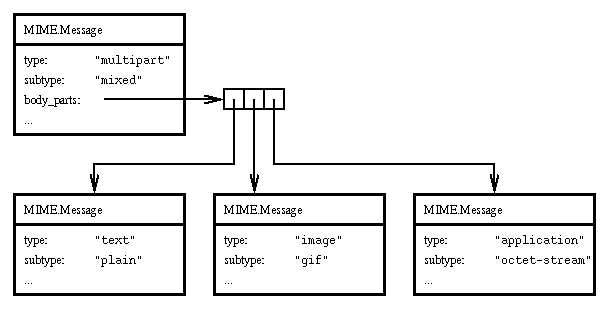
multipart, the process is of course repeated recursively. The following
figure illustrates a multipart message containing three parts, one of
which contains plain text, one containing a graphical image, and the third
containing raw uninterpreted data:
The result is returned in the form of an array containing two elements.
The first element is a mapping containing the headers found. The second
element is a string containing the body.
Should the function succeed in reconstructing the original message, a
new MIME.Message object is returned. Note that this message may
in turn be a part of another, larger, fragmented message.
If the function fails to reconstruct an original message, it returns an
integer indicating the reason for its failure:
The set of special-characters is the one specified in RFC1521 (i.e. "<",
">", "@", ",", ";", ":", "\", "/", "?", "="), and not the one
specified in RFC822.
14.11.1 Global functions
The encoding string is not case sensitive.
> Array.map("=?iso-8859-1?b?S2lscm95?= was =?us-ascii?q?h=65re?="/" ",
MIME.decode_word);
Result: ({ /* 3 elements */
({ /* 2 elements */
"Kilroy",
"iso-8859-1"
}),
({ /* 2 elements */
"was",
0
}),
({ /* 2 elements */
"here",
"us-ascii"
})
})
void|int no_linebreaks);
The encoding string is not case sensitive. For the x-uue encoding,
an optional filename string may be supplied. If a nonzero value is passed
as no_linebreaks, the result string will not contain any linebreaks
(base64 and quoted-printable only).
> MIME.encode_word( ({ "Quetzalcoatl", "iso-8859-1" }), "base64" );
Result: =?iso-8859-1?b?UXVldHphbGNvYXRs?=
> MIME.encode_word( ({ "Foo", 0 }), "base64" );
Result: Foo
type subtype text plain message rfc822 multipart mixed
> MIME.quote( ({ "attachment", ';', "filename", '=', "/usr/dict/words" }) );
Result: attachment;filename="/usr/dict/words"
This function will analyze a string containing the header value, and produce
an array containing the lexical elements. Individual special characters
will be returned as characters (i.e. ints). Quoted-strings,
domain-literals and atoms will be decoded and returned as strings.
Comments are not returned in the array at all.
> MIME.tokenize("multipart/mixed; boundary=\"foo/bar\" (Kilroy was here)");
Result: ({ /* 7 elements */
"multipart",
47,
"mixed",
59,
"boundary",
61,
"foo/bar"
})